
在ROS下对于语音端点检测节点来说,只发布了是否有语音的信号,那么在多节点运作的过程中,系统对于每个节点的调度可以说相对随机,也就是说节点被系统调度运行与节点被启动的时间先后顺序无关,那么如何确保当语音端点检测后发出端点信号时该语音帧不丢失呢?再者又如何保存数据,并将语音数据接入第三方云平台实现语音识别?本文主要来解决这两个问题。
总体方案
首先了解到不同的语音云平台接入方案有所不同。就百度和讯飞两家来说,百度提供的是以音频文件作为请求输入,而讯飞SDK则提供音频块与音频文件接入方案;并且在语音识别、语音合成、语义理解等接入服务中都需要设置相关参数,不同平台的设置方法不相同。而本次设计的目标是能够灵活的配置不同的接入方案,那么怎么解决这个问题才比较合适呢?
这里面存在几个问题需要解决:
- 音频数据完整性问题
- 音频数据输入问题
- 请求参数设置问题
根据以上的分析,那么第一个问题要解决的就是数据输入完整性问题,因为在之前开发的音频端点检测节点只是负责检测是否有语音激活这个功能,并没有将音频数据一起发送出来。其实这个节点也是可以改写的,在语音端点检测之后顺便把相关的音频数据帧通过消息发送出来,可我并没有这么处理,原因还是那个问题,每个节点处理的任务尽可能的小,让颗粒度尽量小。这有什么好处呢?肯定有的,假如说我觉得端点检测这个节点的性能不行,那么我只需要再开发一个以另一种方法检测语音端点的节点并以相同的消息发不出去,这样就不会对系统整个运作造成影响了。那么要让数据让检测到端点的数据块不会被丢弃掉,肯定需要一种缓存的方法来存放某个时刻的音频数据了。这可以有多种解决方法,可以通过缓存文件,循环缓冲区等形式,这里选择了循环缓存的形式来存储音频帧。
第二个问题就是如何选择数据的输入方式,这个比较好解决,若想在识别中以音频块的方式输入,那么只需要订阅一个以音频块作为消息发布的节点即可,同理,若需要文件,则将识别节点订阅相关文件即可。
至于如何设置请求参数,想必你也会想到以文件来配置是最简单快捷,那么接着的问题是用哪种文件来配置会比较好点。不同的人也有不同的想法,那么这次选择 JSON配置文件进行配置,原因比较简单,在 C++ 和 Python 中都有对其提供开源库,并且简单易用。
总体思路就是这样,接下来就是如何实现的问题。
桥梁搭建
缓存管理控制
为解决上面提到的保持数据完整问题,这里创建了一个新的功能包,主要用于管理缓存和文件如下:
catkin_create_pkg audio_brige rospy roscpp std_msgs audio_msgs
在开始动手前,我们想把整体的通信框架给框一下,思路就出来了。
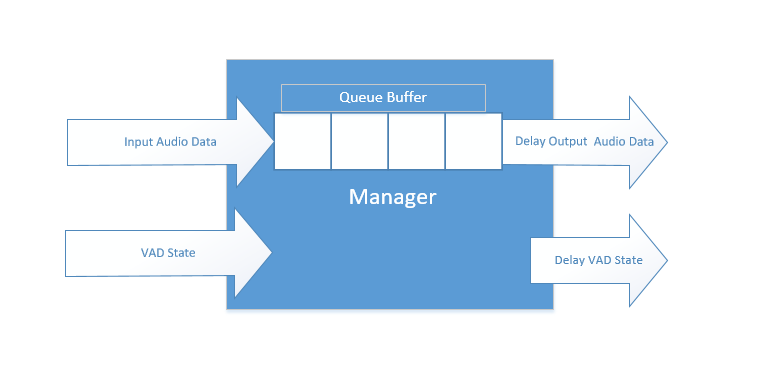
上图中可以看出,这个节点订阅了audio_capture包中的音频块数据消息作为输入,该输入直接进入一个固定长度的缓存中,该缓存以队列的形式存放数据。除了订阅数据消息之外,该节点还订阅了VAD状态消息。该功能包具体是如何操作的呢?缓存区大小又该如何设置好?
首先说明以下缓冲区的作用:将数据在时间轴上向后移动一段时间,这段时间的计算也比较简单;假如
在采样频率16K与样本长度16Bit的情况下,要缓存20ms数据,那么缓冲区设置大小就是:
也就是需要 320个 short型的数组来存放。这里的用意就是缓存语音端点出现前的20ms音频帧,这样在检测到语音时,该节点通过订阅VAD节点,获取当前语音活性状态,当端点出现之后就可以利用缓冲区中的数据构造一个新的延迟音频数据包,这样就能达到让音频数据在时间轴上后退的效果。
这里面一个细节需要注意,就是订阅了两个消息节点,要达到效果上的同步,改变状态最后都在一个节点的回调函数中,也就是说不要在 VAD检测的回调函数中改变起始状态,又在数据接受回调函数中改变起始状态,这样会导致一个严重的BUG出现,因为你无法确定回调究竟是哪个先执行。另外,在具体实现语音帧延后之后,可以再创建一个消息文件,用于绑定 VAD 状态和延迟音频数据;这样在接下去的功能节点中,只需要简单的订阅一个消息类型的节点就可以了。
缓冲区的设计也相对简单,利用Python和C++都比较容易实现,下面简单用C++的链表来实现,当然也可以用双端队列或队列的方式。
STL 链表实现循环缓冲区:
/*
* 参数说明:
* src:数据源
* des: 缓存空间
*/
void circlebuf(std::vector<int>& src,std::list<int>& des)
{
for(int i=0;i<src.size();i++)
{
des.pop_front();
des.push_back(data[i]);
}
}
这里边每次输入都是数据块形式,每次都会更新数据块对应长度的缓存。先进先出嘛。至于具体细节,有兴趣可参阅详细代码实现:缓存节点设计
文件管理
在解决了数据完整性问题后,接下去要解决的一个问题是音频文件的保存问题。讯飞和百度同时支持文件识别,至于文件格式有多种,这里采用的是WAV和PCM的音频格式来保存,两种格式就相差一个音频头而已,比较容易处理。还是先看看这个文件管理节点的输入和输出框图:
同样,文件要保证数据完整,那就需要从缓存节点中套取数据之后在进一步加工。里面的细节也有要考虑的地方,文件要保存多少合适?文件在后续处理会不会用到?这两个问题个人想了一下,仅有一个肯定不行,考虑到在对音频识别的期间又有新的语言输入,那不是要跪?其实不会,原因是ROS的消息通信是以先进先出的队列来处理的,只要是识别够快,那就会跨过这个问题,若慢,音频文件的内容早被更新了..所以简单多加几个文件来的保险,然后依次刷新文件内容就好了,另外若需要收集一些音频文件,只要再写个节点来将这些文件拷贝存放起来也比较省事,这些文件可以用于后续训练提取相关特征参数。
这个节点的任务就是:
1.拿数据,拿VAD状态
2.包装数据
3.发布最新生成的文件路径消息
具体细节,有兴趣可参阅详细代码实现:文件管理
对语音进行识别的中间节点功能已经阐述清楚了,接下来就是如何使用配置文件并接入百度讯飞语音云平台中。下一篇博文将详细介绍。